How to Use Modules¶
Modules¶
Unidata works on the basis of a simple module system. New functionality can be added to the platform by implementing a new module. A module is a part of code packaged in a jar file that implements the org.unidata.mdm.system.type.module.Module interface. In addition, the module must have a special entry in the MANIFEST.MF file, denoting the implementing class, such as the following:
Unidata-Module-Class: org.unidata.mdm.data.module.DataModule
The org.unidata.mdm.system.type.module.Module interface has several mandatory implementation methods.
/**
* Gets module ID, i. e. 'org.unidata.mdm.core'.
* @return ID
*/
String getId();
/**
* Gets module version, consisting of major.minor.rev, i. e. '5.4.3'.
* @return version
*/
String getVersion();
/**
* Gets module localized name, 'Unidata Core'.
* @return name
*/
String getName();
/**
* Gets module localized description, i. e. 'This outstanding module is for all the good things on earth...'.
* @return description
*/
String getDescription();
If the module has dependencies on other modules, it must also implement this method:
/**
* Returns the dependencies of this module.
*/
Collection<Dependency> getDependencies()
The module service will check and load dependencies before running the module.
Note
The module ID must match the module root package if the module uses Spring and injects beans from other modules. The reason is simple - the module root package will be scanned by Spring to detect classes annotated with Spring stereotypes. The class implementing org.unidata.mdm.system.type.module.Module does not have to be a bean itself, although @Autowire or JSR330 @inject can be used within the implementing class.
Regardless of how the module interface is implemented - using Spring or not - the @ModuleRef annotation can be used to inject an instance of a module into the location of interest, as is done here:
@ModuleRef
private DataModule dataModule;
// or
@ModuleRef("org.unidata.mdm.data")
private Module dataModule;
There are also a few other important methods that you might wish to implement:
/**
* Runs module's install/upgrade procedure.
* Can be used to init / mgirate DB schema or other similar tasks.
*/
default void install() {
// Override
}
/**
* Runs module's uninstall procedure.
* Can be used to drop schema or similar tasks.
*/
default void uninstall() {
// Override
}
/**
* Runs module's start procedure.
* Happens upon each application startup.
* Should be used for initialization.
*/
default void start() {
// Override
}
/**
* Runs module's stop procedure.
* Happens upon each application shutdown.
* Should be used for cleanup.
*/
default void stop() {
// Override
}
The general way to write modules is to:
Use a separate database schema for each module if the module uses a database;
Have separate i18n resources;
Have and use your own ExceptionIds.
Pipelines¶
Pipelines provide a way to configure and run a series of operations on a request context object, which is inherited from org.unidata.mdm.system.context.PipelineExecutionContext. Such a member operation is called a “segment” and can be of different types: Start, Point, Connector or Finish. A properly configured pipeline must have a Start segment, can have any number of Point and Connector segments, and must be closed by a Finish segment.
Pipelines can be configured programmatically and then either used for direct calls or saved for caching and future use. Below is an example of such a configuration and subsequent call to save data:
Pipeline p = Pipeline.start(pipelineService.start(RecordUpsertStartExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertValidateExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertSecurityExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertPeriodCheckExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertResolveCodePointersExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertMeasuredAttributesExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertModboxExecutor.SEGMENT_ID)) // <- Modbox create
.with(pipelineService.point(RecordUpsertLobSubmitExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertMergeTimelineExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertIndexingExecutor.SEGMENT_ID))
.with(pipelineService.point(RecordUpsertPersistenceExecutor.SEGMENT_ID))
.end(pipelineService.finish(RecordUpsertFinishExecutor.SEGMENT_ID));
UpsertRecordDTO result = executionService.execute(p, ctx);
Pipelines can be saved using the org.unidata.mdm.system.service.PipelineService.savePipeline(…) and then retrieved using the org.unidata.mdm.system.service.PipelineService.getPipeline(…).
Pipelines are executed using calls to org.unidata.mdm.system.service.ExecutionService.execute(…), which return a subclass of org.unidata.mdm.system.dto.PipelineExecutionResult.
In a simple way, the pipeline segment type hierarchy can be represented as follows:
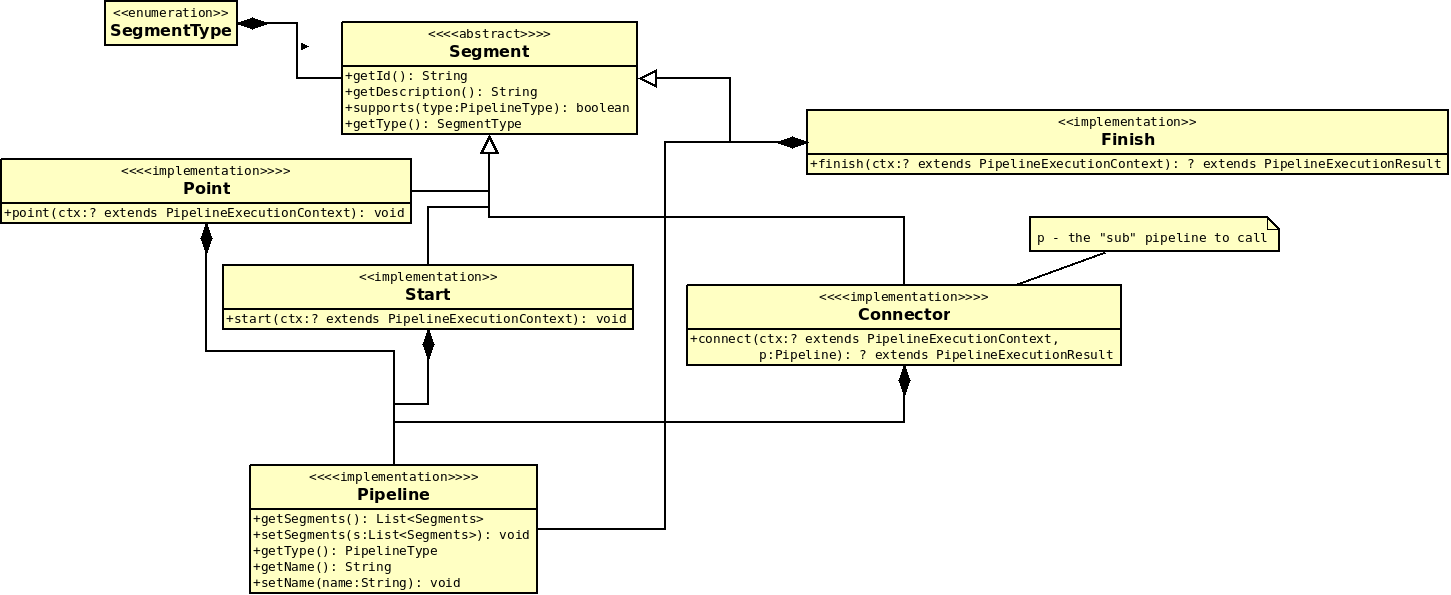
Figure. Pipeline segment types hierarchie¶